
Árbol R * - R* tree
| Árbol R * | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Inventado | 1990 | ||||||||||||||||
| Inventado por | Norbert Beckmann, Hans-Peter Kriegel , Ralf Schneider y Bernhard Seeger | ||||||||||||||||
| Complejidad del tiempo en notación O grande | |||||||||||||||||
| |||||||||||||||||
En el procesamiento de datos, los árboles R * son una variante de los árboles R utilizados para indexar información espacial. Los árboles R * tienen un costo de construcción ligeramente más alto que los árboles R estándar, ya que es posible que sea necesario reinsertar los datos; pero el árbol resultante normalmente tendrá un mejor rendimiento de consulta. Al igual que el árbol R estándar, puede almacenar datos espaciales y puntuales. Fue propuesto por Norbert Beckmann, Hans-Peter Kriegel , Ralf Schneider y Bernhard Seeger en 1990.
Diferencia entre árboles R * y árboles R

La minimización tanto de la cobertura como de la superposición es fundamental para el rendimiento de los árboles R. La superposición significa que, en la consulta o inserción de datos, es necesario expandir más de una rama del árbol (debido a la forma en que los datos se dividen en regiones que pueden superponerse). Una cobertura minimizada mejora el rendimiento de la poda, lo que permite la exclusión de páginas completas de la búsqueda con más frecuencia, en particular para consultas de rango negativo. El árbol R * intenta reducir ambos, utilizando una combinación de un algoritmo de división de nodos revisado y el concepto de reinserción forzada en el desbordamiento del nodo. Esto se basa en la observación de que las estructuras de árbol R son muy susceptibles al orden en el que se insertan sus entradas, por lo que es probable que una estructura construida por inserción (en lugar de cargada a granel) sea subóptima. La eliminación y reinserción de entradas les permite "encontrar" un lugar en el árbol que puede ser más apropiado que su ubicación original.
Cuando un nodo se desborda, una parte de sus entradas se eliminan del nodo y se vuelven a insertar en el árbol. (Para evitar una cascada indefinida de reinserciones causada por el desbordamiento de nodos subsiguiente, la rutina de reinserción se puede llamar solo una vez en cada nivel del árbol cuando se inserta una nueva entrada). Esto tiene el efecto de producir más grupos bien agrupados de entradas en los nodos, reduciendo la cobertura del nodo. Además, las divisiones de nodos reales a menudo se posponen, lo que hace que aumente la ocupación promedio de nodos. La reinserción puede verse como un método de optimización incremental del árbol desencadenado por el desbordamiento de un nodo.
Actuación
- La heurística de división mejorada produce páginas más rectangulares y, por lo tanto, mejores para muchas aplicaciones.
- El método de reinserción optimiza el árbol existente, pero aumenta la complejidad.
- Soporta de manera eficiente datos espaciales y puntuales al mismo tiempo.

R-Tree con división cuadrática de Guttman.
Hay muchas páginas que se extienden de este a oeste en toda Alemania y las páginas se superponen mucho. Esto no es beneficioso para la mayoría de las aplicaciones, que a menudo solo necesitan un área rectangular pequeña que se cruza con muchos cortes.
R-Tree con división lineal Ang-Tan.
Si bien los cortes no se extienden tanto como con Guttman, el problema del corte afecta a casi todas las páginas de la hoja. Las páginas hoja se superponen poco, pero las páginas de directorio sí.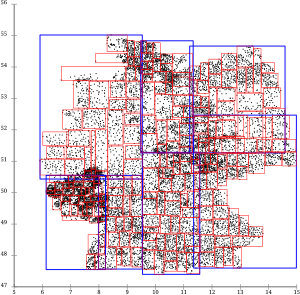
División topológica del árbol R * .
Las páginas se superponen muy poco ya que el árbol R * intenta minimizar la superposición de páginas y las reinserciones optimizan aún más el árbol. La estrategia de división tampoco prefiere las secciones, por lo que las páginas resultantes son mucho más útiles para las aplicaciones de mapas comunes.



Algoritmo y complejidad
- El árbol R * utiliza el mismo algoritmo que el árbol R normal para las operaciones de consulta y eliminación.
- Al insertar, el árbol R * utiliza una estrategia combinada. Para los nodos de hoja, la superposición se minimiza, mientras que para los nodos internos, la ampliación y el área se minimizan.
- Al dividir, el árbol R * utiliza una división topológica que elige un eje dividido en función del perímetro y luego minimiza la superposición.
- Además de mejorar la estrategia de división, el R * -tree también trata de evitar escisiones volviendo a insertar objetos y subárboles al árbol, inspirado en el concepto de equilibrio de un árbol-B .
En el peor de los casos, la complejidad de la consulta y la eliminación son idénticas al R-Tree. La estrategia de inserción en el árbol R * es más compleja que la estrategia de división lineal ( ) del árbol R, pero menos compleja que la estrategia de división cuadrática ( ) para un tamaño de página de objetos y tiene poco impacto en la complejidad total . La complejidad total de la inserción sigue siendo comparable a la del árbol R: las reinserciones afectan como máximo a una rama del árbol y, por lo tanto , las reinserciones, comparable a realizar una división en un árbol R regular. Entonces, en general, la complejidad del árbol R * es la misma que la de un árbol R regular.





Una implementación del algoritmo completo debe abordar muchos casos de esquina y situaciones vinculadas que no se analizan aquí.
Referencias
enlaces externos
-
 Medios relacionados con el árbol R * en Wikimedia Commons
Medios relacionados con el árbol R * en Wikimedia Commons